上一篇我們的基因體時代-AI, Data和生物資訊 Day02- 機器學習在生物資訊中之應用介紹了機器學習在生物資訊中的一些常見應用,以及相關挑戰,其中一個挑戰就是這類模型本身的偏差,可能會造成使用者的倫理問題,因為模型是由資料所決定的,而當資料收集本身有偏差的時候,也會有所影響,尤其是在基因體學中,比如目前大部分的基因體資料都是來自於白種人為主,其中黑人所佔的比重相當低的,相對的目前很多基因預測的結果可能不適用於黑人群體,這邊往下去機器學習在基因醫學中通常是要用來回答什麼問題,還有資料粗略長什麼樣子。
基因醫學領域的研究說白了就是在研究儲存在細胞中DNA序列的功能和資訊是如何影響生物體,並且是否可以用這些資訊來客製化一個人的治療計畫。機器學習剛好蠻適合在這領域來一展所長的,可以用來讓人們有更好的生活以及幫忙開發治療疾病的技術。
我們看一下鼎鼎大名BRCA1基因序列的部分:
可以看到裡面由四個字符組合而成,分別是A、T、C、G,也可以看到似乎裡面有些規律可言(才怪xd可以肉眼看出來的話,那鐵定是在說謊),這些序列除了長度非常長以外,還必須要用相關生物背景才會比較容易來進一步理解它。下面是稍微把這些超過八萬長度序列,放入一些生物的意義進去:
首先,其實對於一個沒有基本生物知識的資料科學家來說,這還是.....無字天書,所以我們進一步皆是解釋一下,正常來說,DNA在生物內部,會先轉換成RNA,最後才變成蛋白質,但是不是來自於單個基因的所有DNA序列都會轉換成蛋白質,部分會轉換成蛋白質的區塊稱作外顯子,不會轉換成蛋白質的區塊稱作內顯子,現在重新來看一下上面的圖片:
現在應該就比較能體會到,其中的複雜度,原來一連串的字串,其有的區域會產生蛋白質片段,有的不會,這其實是必須靠實驗來取得數據,不過多虧目前基因體學相關的研究方法很進步,這類的資訊大量累積中,所以會發現這個圖還有一個玄機:
他有很多種切分這個區塊的版本,這還沒有加上每個人這區域的基因可能有部分位點的差異進去,分享到這邊應該可以稍微感到這領域富含很多值得用機器學習的方法來回答的問題!
一個人的基因體大概有30億個鹼基序列長度,裡面有大概20000個會產生蛋白質的基因,還有25000個不會產生蛋白質的基因,有的基因很重要,有的基因到現在還不知道扮演什麼角色,下面這張來自Barabasi Lab的圖片(2021. A wealth of discovery built on the Human Genome Project - by the numbers, Nature)
這張視覺化的圖片,很酷炫的用冰山來表達我們對於基因的理解,冰山的直徑是相關疾病的數量,高度則是相關的論文發表,可以發現大多數的研究集中在少數的基因,而大部分的基因直到現在都是未知功能的。
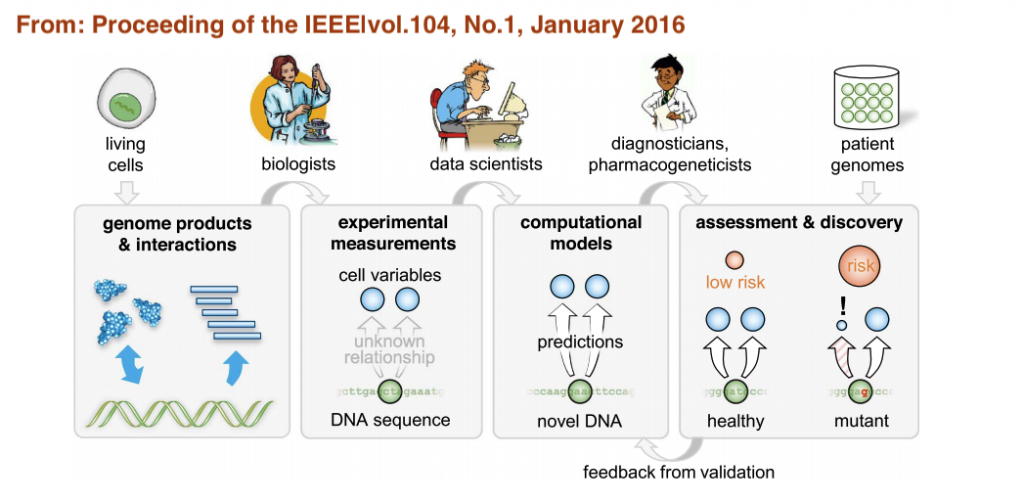
從這張圖很好的顯示了如何建立這個複雜模型的方式,他是需要跨領域的團隊合作,上面是要參與的人,下面則是希望建立的模型類型,我們必須擁有良好的模式細胞,並且生物學家們設計實驗來測試他們的功能,接者會取得大量數據,此時資料科學家能根據這些數據來進行建模,這些模型再跟臨床場域專家來看是否能用做臨床服務,同時也能收集實際病人的基因資訊(雖然這是一個簡化的閉環,實際參與其中的團隊可能更為複雜!)
這個月的規劃貼在這篇文章中我們的基因體時代-AI, Data和生物資訊 Overview,也會持續調整!我們的基因體時代是我經營的部落格,如有對於生物資訊、檢驗醫學、資料視覺化、R語言有興趣的話,可以來交流交流!

